- Nederland
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Wat is een NPU en hoe werkt deze in AI-apparaten?
Catalogus

Wat is een NPU?
Een Neural Processing Unit (NPU) is een gespecialiseerde processor die is ontworpen om kunstmatige-intelligentietaken efficiënter af te handelen dan een processor voor algemene doeleinden.De belangrijkste rol ervan is het versnellen van neurale netwerkbewerkingen die worden gebruikt in functies zoals beeldherkenning, stemverwerking, objectdetectie en realtime AI-inferentie.In tegenstelling tot een CPU, die is gebouwd om veel verschillende computertaken te beheren, is een NPU gericht op AI-gerelateerde berekeningen.Het is geoptimaliseerd om grote hoeveelheden gegevens tegelijkertijd te verwerken, waardoor het geschikt is voor workloads die snelle patroonherkenning en besluitvorming vereisen.Op moderne apparaten zorgen NPU's ervoor dat AI-functies rechtstreeks op lokale hardware kunnen worden uitgevoerd in plaats van volledig afhankelijk te zijn van cloudservers.Hierdoor kunnen smartphones, slimme camera's, robots, voertuigen en edge-apparaten sneller reageren en minder stroom verbruiken.Hierdoor zijn NPU's een belangrijk onderdeel geworden van moderne intelligente systemen.
Kernarchitectuur en verwerkingsmodules van een NPU
Een NPU is opgebouwd uit verschillende gespecialiseerde hardwaremodules die samenwerken om de werkbelasting van neurale netwerken snel en efficiënt te verwerken.In plaats van elke bewerking via één universele processor te sturen, wordt de werklast verdeeld over speciale hardwareblokken die gegevens continu parallel verwerken.Deze structuur verbetert de inferentiesnelheid van AI, vermindert onnodige gegevensbewegingen, verlaagt het energieverbruik en helpt het efficiënte geheugengebruik te behouden.
Tijdens de AI-verwerking doorlopen gegevens meerdere fasen binnen de processor.Invoergegevens komen eerst in de computerpijplijn terecht, waar grootschalige wiskundige bewerkingen worden uitgevoerd.Tussenresultaten doorlopen vervolgens activeringsverwerking, tensorversnelling, beeldgerelateerde bewerkingen en hardware voor geheugenoptimalisatie voordat de uiteindelijke uitvoer wordt geproduceerd.Omdat deze modules in een gecoördineerde volgorde samenwerken, kan de NPU een hoge doorvoer behouden, zelfs bij het uitvoeren van grote neurale netwerkmodellen.
Kerncomputer- en activeringsmodules
De belangrijkste rekenmachine binnen een NPU is de Multiply-Accumulate (MAC) -eenheid.De meeste neurale netwerkworkloads voeren herhaaldelijk vermenigvuldiging en optelling uit over zeer grote datasets, dus deze hardware verwerkt het grootste deel van de AI-berekeningen tijdens inferentie.Wanneer invoergegevens een neuraal netwerk binnenkomen, worden waarden vermenigvuldigd met opgeslagen gewichtswaarden en vervolgens bij elkaar opgeteld om nieuwe uitvoer te genereren.Dit proces herhaalt zich voortdurend over vele neurale netwerklagen.
Moderne NPU's bevatten vaak honderden of duizenden MAC-eenheden die tegelijkertijd werken.In plaats van één bewerking tegelijk te berekenen, verdeelt de hardware de werklast over vele parallelle uitvoeringspaden.Grote hoeveelheden AI-gegevens gaan samen door de processor, waardoor de inferentiesnelheid aanzienlijk wordt verbeterd en de latentie laag blijft.In beeldherkenningssystemen scannen MAC-eenheden bijvoorbeeld herhaaldelijk groepen pixels en combineren ze filterwaarden om randen, texturen, vormen en patronen te detecteren.In taalmodellen voert dezelfde hardware grootschalige vector- en matrixbewerkingen uit om tokens en relaties tussen woorden te verwerken.
Nadat deze wiskundige berekeningen zijn voltooid, gaan de resultaten naar de module Activeringsfunctie.Neurale netwerken zijn afhankelijk van niet-lineaire activeringsfuncties om complexe relaties binnen gegevens te verwerken.Zonder activeringsverwerking zou het netwerk alleen eenvoudige lineaire berekeningen uitvoeren en geavanceerde AI-taken niet effectief kunnen verwerken.
Deze module voert functies zoals ReLU, Sigmoid en Tanh rechtstreeks in de hardware uit.Binnenkomende waarden worden snel getransformeerd volgens de geselecteerde activeringsregel.ReLU verwijdert bijvoorbeeld negatieve waarden terwijl positieve outputs behouden blijven, waardoor het netwerk zich tijdens inferentie kan concentreren op sterkere featuresignalen.Omdat activeringsverwerking herhaaldelijk plaatsvindt in elke neurale netwerklaag, helpt speciale versnellingshardware vertragingen te verminderen en te voorkomen dat de belangrijkste rekeneenheden overbelast raken.
Tensor- en ruimtelijke gegevensverwerkingsmodules
NPU's bevatten ook gespecialiseerde hardware voor het afhandelen van tensoroperaties en de verwerking van ruimtelijke gegevens.Bijna elk modern AI-model is gebaseerd op tensoren, dit zijn multidimensionale datastructuren die worden gebruikt om informatie over dimensies zoals breedte, hoogte, kanalen, kenmerklagen en batches te ordenen.Grote hoeveelheden tensorgegevens bewegen tijdens gevolgtrekking voortdurend tussen neurale netwerklagen.
De Tensor Acceleration Unit verwerkt deze tensorstructuren direct in hardware.Bewerkingen zoals tensorvermenigvuldiging, hervorming, transformatie en accumulatie worden veel sneller uitgevoerd dan op algemene processors.Deze specifieke versnelling wordt vooral belangrijk in transformatorarchitecturen, computervisiesystemen, grote taalmodellen en realtime AI-toepassingen die een zeer hoge doorvoer vereisen.
Naast tensorverwerking bevatten NPU's ook modules die zijn ontworpen voor 2D- en ruimtelijke gegevensbewerkingen die vaak worden gebruikt in beeld- en videowerklasten.Computer vision-systemen passen voortdurend grote hoeveelheden pixelgegevens aan, reorganiseren, filteren en verplaatsen voordat de diepere AI-analyse begint.Het afzonderlijk uitvoeren van deze taken verbetert de efficiëntie en vermindert de druk op de hoofdcomputer.
Tijdens de beeldverwerking beheert de hardware bewerkingen zoals downsampling, verplaatsing van featuremaps, kopiëren van afbeeldingen, vergroten/verkleinen, bijsnijden en overdracht van ruimtelijke gegevens.Video met hoge resolutie die door een camera is vastgelegd, kan bijvoorbeeld eerst worden verkleind en gereorganiseerd voordat deze in de neurale netwerkpijplijn terechtkomt.Dit vermindert de rekenbelasting terwijl belangrijke visuele informatie behouden blijft die nodig is voor objectdetectie en scèneanalyse.
Geheugenoptimalisatie en datacompressiemodules
Moderne AI-modellen vereisen grote hoeveelheden geheugen om neurale netwerkgewichten, tensoren en tussenliggende gegevens op te slaan.Het voortdurend overbrengen van deze informatie tussen geheugen en computerhardware verhoogt het bandbreedtegebruik, de latentie en het stroomverbruik.Om deze overhead te verminderen, bevatten NPU's speciale datacompressie- en decompressiemodules.
Voordat gegevens in het geheugen worden opgeslagen, worden herhaalde patronen en gewichtswaarden gecomprimeerd in kleinere formaten.Tijdens de uitvoering wordt de gecomprimeerde informatie snel hersteld en rechtstreeks naar de computerpijplijn gestuurd.Dit vermindert het geheugenverkeer en zorgt ervoor dat meer AI-gegevens in het snelle lokale geheugen blijven, dichter bij de processor.
Geavanceerde compressiemethoden kunnen de modelgrootte vaak meerdere keren verkleinen, terwijl vrijwel dezelfde gevolgtrekkingsnauwkeurigheid behouden blijft.Dit wordt vooral belangrijk bij smartphones, embedded systemen, slimme camera's, draagbare elektronica en andere edge AI-apparaten waar de geheugencapaciteit en energie-efficiëntie beperkt zijn.
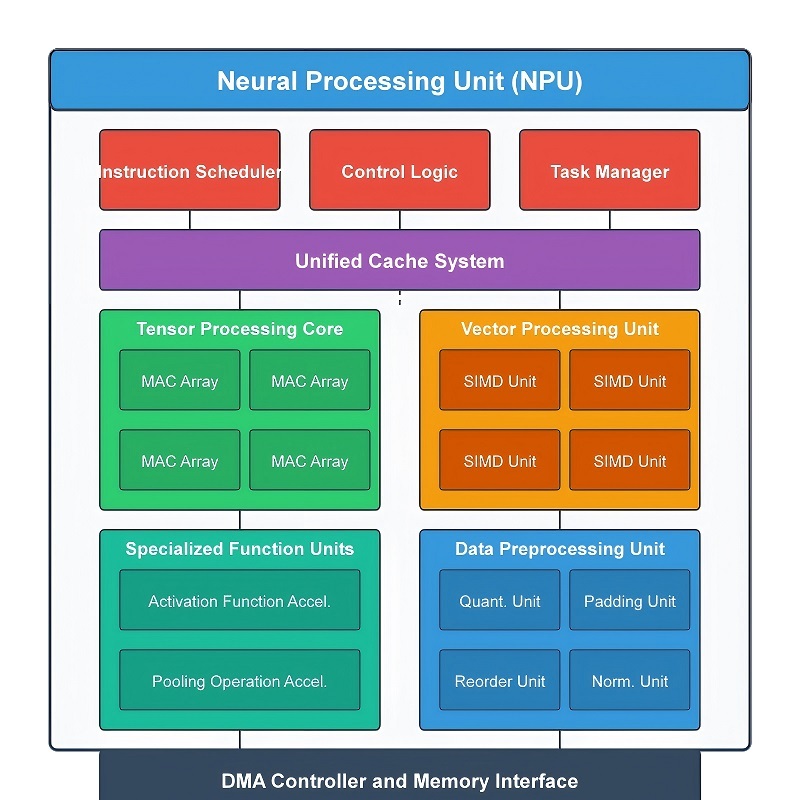
Hoe deze modules samenwerken
De prestaties van een NPU zijn niet afhankelijk van een enkel hardwareblok.De efficiëntie komt voort uit de manier waarop alle verwerkingsmodules samenwerken als een gecoördineerde pijplijn.
Een typische AI-werklast begint met grootschalige wiskundige berekeningen binnen de MAC-eenheden.Tussenresultaten passeren vervolgens de activeringsverwerking om niet-lineair gedrag in het neurale netwerk te introduceren.Tensor-versnellingshardware organiseert en verwerkt continu multidimensionale gegevens door de hele pijplijn, terwijl ruimtelijke verwerkingsmodules beeld- en videogerelateerde bewerkingen beheren.Tegelijkertijd vermindert compressiehardware de overhead van geheugenoverdracht op de achtergrond.
Omdat deze bewerkingen gelijktijdig via speciale hardwarepaden worden uitgevoerd, kan de NPU grote AI-workloads verwerken met een hoge doorvoer, lagere latentie en een veel betere energie-efficiëntie dan traditionele processors.
NPU's in smartphones en mobiele AI
Moderne smartphones verwerken elke seconde een enorm aantal handelingen.Een telefoon kan vrijwel onmiddellijk worden ontgrendeld met gezichtsherkenning, de camera openen, foto's verwerken, spraak vertalen en AI-ondersteunde applicaties uitvoeren.Om dit prestatieniveau te ondersteunen in dunne mobiele apparaten met een beperkte batterijcapaciteit, vertrouwen smartphones op sterk geïntegreerde System-on-Chip (SoC)-architecturen.
Binnen de SoC werken meerdere processors samen, en elke processor is geoptimaliseerd voor een andere werklast.De CPU beheert de systeemcontrole, applicaties en algemene computertaken.De GPU zorgt voor grafische weergave, gaming en visuele verwerking.De NPU (Neural Processing Unit) richt zich specifiek op AI-berekeningen.
In plaats van neurale netwerkwerklasten via de CPU of GPU te routeren, sturen smartphones veel AI-taken naar de NPU, waar de hardware is geoptimaliseerd voor snelle parallelle AI-verwerking.Deze scheiding verbetert de efficiëntie omdat elke processor het soort werklast verwerkt waarvoor hij is ontworpen.Als gevolg hiervan kunnen smartphones geavanceerde AI-bewerkingen uitvoeren met snellere responstijden, lagere latentie en betere energie-efficiëntie.
Hoe NPU's de AI van smartphones veranderden
Voordat mobiele NPU's gemeengoed werden, waren veel AI-functies van smartphones sterk afhankelijk van cloud computing.Voor taken zoals stemherkenning, taalvertaling, beeldverbetering en intelligente assistenten moesten gegevens vaak naar externe servers worden geüpload om te worden verwerkt voordat de resultaten naar het apparaat werden teruggestuurd.Dit zorgde voor vertragingen, meer netwerkverkeer en verhoogde privacyproblemen.
De introductie van speciale mobiele NPU's heeft deze workflow aanzienlijk veranderd.AI-modellen kunnen nu rechtstreeks op de smartphone zelf draaien, waardoor veel bewerkingen lokaal in realtime kunnen worden uitgevoerd in plaats van volledig afhankelijk te zijn van externe servers.
Deze verschuiving leverde een aantal grote voordelen op:
• Lagere latency omdat data niet langer constante cloudcommunicatie nodig heeft
• Snellere AI-responstijden tijdens realtime operaties
• Betere privacybescherming omdat gevoelige gegevens op het apparaat kunnen blijven staan
• Lager energieverbruik dankzij hardware die specifiek is geoptimaliseerd voor AI-workloads
• Stabielere AI-prestaties, zelfs met zwakke of niet-beschikbare internetverbindingen
Naarmate mobiele NPU's krachtiger werden, begonnen smartphones voortdurend geavanceerde AI-functies op de achtergrond uit te voeren zonder merkbare vertragingen tijdens dagelijks gebruik.
Hoe smartphones NPU's gebruiken bij echte operaties
AI-fotografie en beeldverwerking
Een van de meest zichtbare toepassingen van mobiele NPU’s is AI-fotografie.Moderne smartphonecamera's vertrouwen niet langer alleen op beeldsensoren en traditionele beeldverwerkingsalgoritmen.AI-modellen analyseren nu continu beeldgegevens terwijl de camera in werking is.
Wanneer de camera-app wordt geopend, begint de smartphone onmiddellijk met het frame voor frame verwerken van de binnenkomende beeldstream.De NPU analyseert in realtime de lichtomstandigheden, objectgrenzen, gezichtsdetails, kleuren, texturen en bewegingspatronen.Op basis van deze analyse past het systeem de belichting, witbalans, HDR-instellingen, scherpte en contrast vrijwel onmiddellijk aan voordat het beeld wordt vastgelegd.
Bij fotografie bij weinig licht combineert de NPU meerdere beeldframes om de helderheid te verbeteren en tegelijkertijd de visuele ruis te verminderen.Tijdens portretfotografie scheidt de processor onderwerpen op de voorgrond van achtergrondgebieden en past diepte-effecten nauwkeuriger toe rond randen zoals haar, brillen en kledingcontouren.
Scèneherkenning is ook sterk afhankelijk van de NPU.De processor vergelijkt beeldpatronen met getrainde AI-modellen om omgevingen zoals voedsel, landschappen, huisdieren, documenten, zonsondergangen of nachtscènes te identificeren.Eenmaal herkend, past de camera automatisch de instellingen aan om de beeldkwaliteit te optimaliseren.
Omdat deze berekeningen rechtstreeks op de smartphone plaatsvinden, voelt AI-fotografie vrijwel onmiddellijk aan, ook al vinden er voortdurend grote hoeveelheden neurale netwerkberekeningen op de achtergrond plaats.
Spraakherkenning en AI-assistenten
Stemassistenten en spraakgerelateerde functies zijn ook sterk afhankelijk van lokale AI-versnelling.Wanneer een gebruiker tegen de smartphone spreekt, vangt de microfoon ruwe audiosignalen op die moeten worden opgeschoond, gescheiden en omgezet in herkenbare spraakpatronen.
De NPU verwerkt de audiostream voortdurend door fonemen te identificeren, achtergrondgeluiden te filteren en geluidspatronen te matchen met spraakherkenningsmodellen.Dankzij lokale AI-verwerking kunnen wekwoorden en veelvoorkomende spraakopdrachten vrijwel onmiddellijk worden gedetecteerd zonder voortdurend audio-opnamen naar cloudservers te verzenden.
Dit verbetert het reactievermogen voor taken zoals:
• Spraakopdrachten
• Realtime spraaktranscriptie
• Taalvertaling
• AI-assistent-interactie
• AI-oproepverbetering
• Ruisonderdrukking tijdens videogesprekken
Omdat een groot deel van de verwerking rechtstreeks op het apparaat plaatsvindt, blijft de spraakinteractie vloeiender, zelfs onder onstabiele netwerkomstandigheden.
AI-gaming en realtime systeemoptimalisatie
Moderne smartphones gebruiken ook NPU's voor gaming-optimalisatie en intelligent systeembeheer.Tijdens het spelen monitoren AI-modellen de vraag naar frameweergave, het werklastgedrag, de thermische omstandigheden, aanraakinvoerpatronen en het batterijgebruik in realtime.
Het systeem kan de GPU-werkbelasting dynamisch aanpassen, de energietoewijzing optimaliseren, de framesnelheden stabiliseren en oververhitting tijdens lange gamesessies verminderen.Sommige smartphones gebruiken ook AI-opschaling en bewegingsvoorspellingstechnieken om de visuele vloeiendheid te verbeteren en tegelijkertijd een lager energieverbruik te behouden.
Buiten gaming helpt de NPU bij het optimaliseren van achtergrondtoepassingen, batterijbeheer, voorspellende gebruikersinteracties en taakplanning op basis van apparaatgebruikspatronen.
Evolutie van mobiele NPU's
De ontwikkeling van mobiele NPU’s versnelde snel naarmate de AI-workloads van smartphones geavanceerder en rekentechnisch veeleisender werden.
|
Periode |
Mobiele NPU-ontwikkeling |
|
2017 - Vroege commerciële mobiele NPU's |
Huawei introduceerde een van de eerste commerciële smartphones
NPU's via de Kirin 970-processor.Dit markeerde een belangrijke verschuiving in de richting van
grootschalige AI-versnelling op het apparaat in consumentensmartphones.In plaats van
voornamelijk afhankelijk van CPU's en GPU's voor AI-taken, inclusief smartphones nu
speciale AI-hardware direct binnen de SoC-architectuur. |
|
2018 — Uitbreiding van AI op het apparaat |
Apple introduceerde de Neural Engine in de A12 Bionic
chip, verbetering van AI-verwerking voor gezichtsherkenning, computationeel
fotografie en intelligente mobiele functies.AI op het apparaat werd een belangrijk onderwerp
focus op de ontwikkeling van vlaggenschipsmartphones. |
|
2019–2020 — Industriebrede AI-integratie |
Grote chipfabrikanten, waaronder Qualcomm, Samsung en
MediaTek begon met het integreren van speciale AI-versnellers in het vlaggenschip mobiel
verwerkers.AI-prestaties begonnen een belangrijke concurrentiefactor te worden
hardwareontwerp voor smartphones. |
|
2021–2023 — AI-verwerking wordt een kernbenchmark |
Smartphonefabrikanten vergeleken NPU steeds vaker
prestaties naast CPU- en GPU-prestaties.NPU's kwamen centraal te staan
computationele fotografie, stem-AI, videoverbetering, batterij-optimalisatie,
en intelligente systeemfuncties. |
|
2024–2025 — Grote AI-modellen die op smartphones draaien |
Moderne mobiele NPU's hebben voldoende verwerkingskracht gekregen om dat te kunnen
ondersteuning van grotere AI-modellen rechtstreeks op smartphones en edge-apparaten.Meer AI
workloads kunnen nu lokaal worden uitgevoerd zonder sterk afhankelijk te zijn van de cloud
infrastructuur, waardoor zowel het reactievermogen als de privacy worden verbeterd. |
Vergelijking van huidige reguliere mobiele NPU's
Moderne vlaggenschip-smartphoneprocessors bevatten nu zeer geavanceerde NPU-architecturen die zijn geoptimaliseerd voor realtime AI-inferentie, hoge doorvoer en verbeterde energie-efficiëntie.
|
Mobiele processor |
NPU-functies |
|
Appel A17Pro |
Bevat een neurale motor met 26 kernen, ontworpen voor snel
AI-verwerking op het apparaat.De architectuur verbetert AI-fotografie, stem
herkenning en realtime intelligente systeemfuncties op Apple-apparaten. |
|
Qualcomm Leeuwebek 8 Gen 3 |
Maakt gebruik van een geüpgradede Hexagon AI-processor die is geoptimaliseerd voor
generatieve AI, neurale netwerkversnelling, geavanceerde beeldverwerking en
efficiënte mobiele AI-workloads. |
|
MediaTek-dimensie 9300 |
Bevat een APU (AI Processing Unit) van de zesde generatie met
grote verbeteringen in de AI-inferentiesnelheid en realtime AI-verwerking
mogelijkheden voor smartphones en edge-apparaten. |
|
Samsung Exynos 2400 |
Beschikt over een mobiele NPU van de volgende generatie, gericht op sneller
AI-verwerking op het apparaat voor computationele fotografie, intelligent systeem
operaties en geavanceerde mobiele AI-toepassingen. |
NPU versus GPU versus CPU: belangrijkste verschillen in AI-verwerking
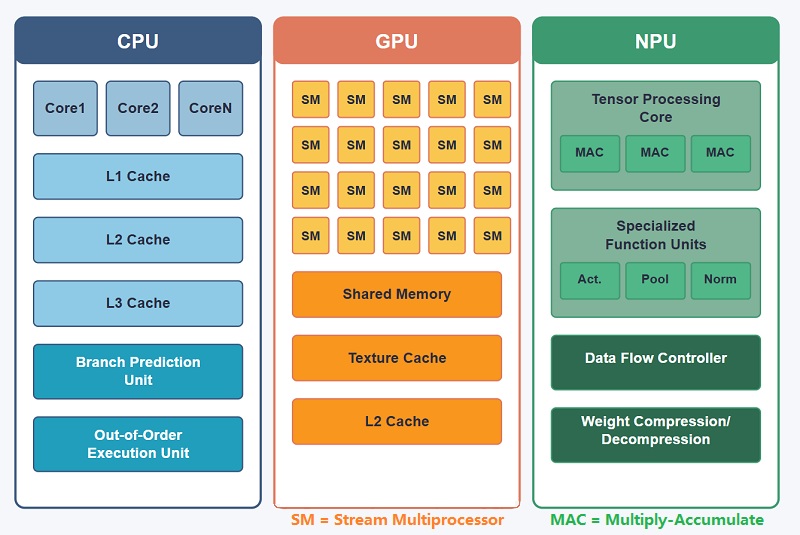
Zowel GPU's als NPU's zijn ontworpen om grote hoeveelheden gegevens parallel te verwerken, maar ze zijn voor heel verschillende doeleinden gebouwd.Een GPU is oorspronkelijk ontwikkeld voor grafische weergave, terwijl een NPU specifiek is gemaakt voor neurale netwerkberekeningen en AI-inferentie. Vanwege dit verschil in ontwerpdoelen gaan de twee processors op heel verschillende manieren om met AI-workloads.GPU's kunnen AI-modellen effectief uitvoeren, vooral in grootschalige trainingssystemen, maar ze hebben nog steeds een groot deel van de complexiteit van een grafische processor.NPU's vereenvoudigen veel van deze bewerkingen door zich bijna volledig te concentreren op AI-gerelateerde berekeningen.
|
Functie |
CPU
(Centrale verwerkingseenheid) |
GPU
(grafische verwerkingseenheid) |
NPU
(neurale verwerkingseenheid) |
|
Hoofddoel |
Algemeen gebruik
computer- en systeemcontrole |
Parallel
graphics en krachtige berekeningen |
AI-inferentie en
versnelling van het neurale netwerk |
|
Primaire werklast |
Operationeel
systemen, applicaties, multitasking |
Grafisch
rendering, AI-training, wetenschappelijk computergebruik |
AI-verwerking,
tensoroperaties, diepgaande leerinferentie |
|
Verwerkingsstijl |
Sequentieel
verwerking |
Enorme parallel
verwerking |
AI-geoptimaliseerd
parallelle verwerking |
|
Kernontwerp |
Weinig krachtige en
flexibele kernen |
Duizenden
parallelle uitvoeringskernen |
Gespecialiseerde AI
versnellingseenheden |
|
AI-prestaties |
Matig |
Hoog |
Zeer hoog voor AI
gevolgtrekking |
|
Matrix
Vermenigvuldigingssnelheid |
Beperkt |
Snel |
Zeer geoptimaliseerd |
|
Tensor
Verwerking |
Softwaregebaseerd |
Ondersteund
door GPU-versnelling |
Toegewijde tensor
versnellingshardware |
|
Energie-efficiëntie |
Lager voor AI
werkdruk |
Matig tot hoog
stroomverbruik |
Zeer krachtig
efficiënt |
|
Warmteopwekking |
Matig |
Hoog onder zwaar
werkdruk |
Lager tijdens AI
gevolgtrekking |
|
Geheugenbandbreedte
Gebruik |
Matig |
Zeer hoog |
Geoptimaliseerd en
verminderd |
|
Latentie in AI
Taken |
Hoger |
Matig |
Zeer laag |
|
Realtime AI
Vermogen |
Beperkt |
Goed |
Uitstekend |
|
Het beste voor AI
Opleiding |
Niet ideaal |
Uitstekend |
Beperkt vergeleken
naar GPU's |
|
Het beste voor AI
Gevolgtrekking |
Basiswerklasten |
Hoge prestaties
gevolgtrekking |
Geoptimaliseerd
realtime gevolgtrekking |
|
Algemeen
Toepassingen |
PC's, servers,
besturingssystemen |
Gamen, AI
training, rendering, simulaties |
Smartphones,
edge AI, robotica, slimme camera's |
|
Afhankelijkheid van
Cloud-AI |
Hoger |
Matig |
Lager vanwege
lokale AI-versnelling |
|
Batterij
Efficiëntie in mobiele apparaten |
Lager |
Matig |
Hoog |
|
Typische apparaten |
Computers,
laptops, servers |
Gaming-pc's, AI
servers, werkstations |
Smartphones, IoT
apparaten, edge AI-hardware |
|
Kosten en
Complexiteit |
Algemeen gebruik
architectuur |
Complex
hoogwaardige architectuur |
Gespecialiseerd
AI-gerichte architectuur |
|
Belangrijkste voordeel |
Flexibiliteit en
systeembeheer |
Grootschalig
parallelle berekening |
Snel en
efficiënte lokale AI-verwerking |
Gespecialiseerde verwerkingseenheden in moderne computers
Afgezien van NPU gebruiken moderne computersystemen veel verschillende soorten processors, omdat geen enkele architectuur elke werklast efficiënt kan verwerken.Sommige processors richten zich op systeemcontrole, sommige zijn gespecialiseerd in grafische weergave, terwijl andere zijn geoptimaliseerd voor AI-versnelling, netwerken, wetenschappelijk computergebruik of ingebedde controle.
In moderne smartphones, servers, industriële systemen, roboticaplatforms, voertuigen en edge-AI-apparaten werken meerdere verwerkingseenheden vaak tegelijkertijd samen.Elke processor verwerkt het type werklast waarvoor hij specifiek is ontworpen, waardoor de prestaties, de energie-efficiëntie en het realtime reactievermogen in moderne computeromgevingen worden verbeterd.
CPU: Centrale verwerkingseenheid
Een CPU (Central Processing Unit) is de hoofdcontroller van de meeste computersystemen.Het beheert besturingssystemen, applicaties, geheugencoördinatie, taakplanning en communicatie tussen hardwarecomponenten.
CPU's zijn zeer flexibel en kunnen veel verschillende werklasten betrouwbaar verwerken, waardoor ze essentieel zijn in computers, smartphones, servers en embedded systemen.Ze zijn echter minder efficiënt voor grootschalige parallelle AI-workloads in vergelijking met meer gespecialiseerde processors.
GPU: grafische verwerkingseenheid
Een GPU (Graphics Processing Unit) is geoptimaliseerd voor grootschalige parallelle verwerking.De architectuur bevat veel uitvoeringskernen die duizenden bewerkingen tegelijkertijd kunnen verwerken.
GPU's zijn oorspronkelijk ontwikkeld voor grafische weergave, maar worden nu veel gebruikt voor AI-training, wetenschappelijke simulatie, videoverwerking en high-performance computing vanwege hun sterke parallelle rekenvermogen.
TPU: Tensorverwerkingseenheid
Een TPU (Tensor Processing Unit) is geoptimaliseerd voor op tensor gebaseerde AI-workloads en grootschalige deep learning-versnelling.Deze processors zijn voornamelijk ontworpen voor cloud AI-infrastructuur en machine learning-omgevingen in datacenters.
TPU's zijn zeer effectief voor:
• Deep learning-training
• Grote AI-modellen
• Tensorberekening
• Cloud AI-diensten
• AI-versnelling met hoge doorvoer
FPGA: herconfigureerbare hardwareverwerking
Een FPGA (Field-Programmable Gate Array) maakt gebruik van programmeerbare logische blokken die na productie kunnen worden geconfigureerd voor specifieke taken.In tegenstelling tot vaste processorarchitecturen maken FPGA's het mogelijk de hardwarefunctie zelf aan te passen.
FPGA's worden veel gebruikt in:
• Communicatiesystemen
• Auto-elektronica
• Industriële automatisering
• Lucht- en ruimtevaartsystemen
• Edge-computing
• Medische hulpmiddelen
DPU: Gegevensverwerkingseenheid
Een DPU (Data Processing Unit) is geoptimaliseerd voor datacentrische workloads binnen cloudinfrastructuur en netwerksystemen.DPU's helpen de CPU-werklast te verminderen door de gegevensverplaatsing, opslagbewerkingen, encryptie en netwerkverkeersbeheer te versnellen.
Deze processors worden vaak gebruikt in:
• Datacentra
• Cloudcomputing
• Hogesnelheidsnetwerken
• Opslagversnelling
• Serverinfrastructuur
VPU: Visieverwerkingseenheid
Een VPU (Vision Processing Unit) is gespecialiseerd in computervisie en beeldgebaseerde AI-verwerking.VPU's versnellen werklasten zoals gezichtsherkenning, objectdetectie, bewegingsregistratie en videoanalyse.
VPU's worden vaak aangetroffen in:
• Slimme camera's
• Bewakingssystemen
• Robotica
• Autonome voertuigen
• AR/VR-systemen
• Edge AI-visieapparaten
IPU: Inlichtingenverwerkingseenheid
Een IPU (Intelligence Processing Unit) is ontworpen voor zeer parallelle AI- en machine learning-workloads.De architectuur richt zich op het verbeteren van de efficiëntie van de gegevensstroom tijdens grootschalige uitvoering van neurale netwerken.
IPU's worden gebruikt voor:
• Versnelling van machinaal leren
• Patroonherkenning
• AI-gevolgtrekking
• Parallelle tensorverwerking
• Geavanceerd AI-onderzoek
BPU: Hersenverwerkingseenheid
Een BPU (Brain Processing Unit) is geoptimaliseerd voor embedded AI en edge intelligence-systemen.Deze processors richten zich op snelle lokale AI-inferentie met een lager energieverbruik.
BPU's worden vaak gebruikt in:
• Slimme detectiesystemen
• Robotica
• Edge AI-hardware
• Bewegingsdetectiesystemen
• Autonome platforms
HPU: Holographic Processing Unit
Een HPU (Holographic Processing Unit) is ontworpen voor holografisch computergebruik, mixed reality en ruimtelijke analysesystemen.
HPU's helpen bij het proces:
• Milieukartering
• Bewegingsregistratie
• Sensorfusie
• Realtime ruimtelijke interactie
• AR/VR-omgevingen
MPU en MCU: ingebedde besturingsverwerking
MPU's (Microprocessor Units) en MCU's (Microcontroller Units) worden veel gebruikt in embedded systemen en elektronica met laag vermogen.
MPU's worden vaak gebruikt in embedded computersystemen die controle op besturingssysteemniveau vereisen, terwijl MCU's processorkernen, geheugen en invoer-/uitvoercontrole integreren in een compacte chip voor speciale taken met laag energieverbruik.
Deze processors worden vaak aangetroffen in:
• IoT-apparaten
• Industriële besturingen
• Auto-elektronica
• Huishoudelijke apparaten
• Draagbare ingebedde systemen
APU: Versnelde verwerkingseenheid
Een APU (Accelerated Processing Unit) combineert CPU- en GPU-functionaliteit in één processorpakket.Deze integratie verbetert de energie-efficiëntie, verkleint de hardwaregrootte en zorgt ervoor dat computer- en grafische werklasten systeembronnen efficiënter kunnen delen.
APU's worden vaak gebruikt in:
• Laptops
• Mini-pc's
• Spelsystemen op instapniveau
• Multimedia-apparaten
• Draagbare computerplatforms
Waarom moderne systemen meerdere gespecialiseerde processors gebruiken
Moderne computersystemen zijn zelden afhankelijk van een enkele processorarchitectuur.In plaats daarvan combineren apparaten meerdere gespecialiseerde processors omdat verschillende werkbelastingen verschillende verwerkingsmethoden vereisen.
Een modern systeem kan bijvoorbeeld gebruik maken van:
• CPU's voor systeemcontrole
• GPU's voor grafische weergave en parallelle berekeningen
• NPU's voor AI-inferentie
• VPU's voor computervisie
• DPU's voor netwerken en gegevensverplaatsing
• MCU's voor ingebedde besturingstaken
Door de werklast over speciale hardware te verdelen, bereiken moderne systemen betere prestaties, lagere latentie, verbeterde energie-efficiëntie en effectievere realtime verwerking in AI-, grafische, netwerk- en embedded computeromgevingen.
Conclusie
NPU's worden essentieel in moderne computers, omdat ze ervoor zorgen dat AI-taken lokaal, snel en efficiënt kunnen worden uitgevoerd zonder sterk afhankelijk te zijn van cloudverwerking.Hun geoptimaliseerde architectuur vermindert de latentie, het stroomverbruik, de geheugenbeweging en de warmteontwikkeling, waardoor ze waardevol zijn in smartphones, robotica, gezondheidszorgapparatuur, industriële automatisering, slimme huizen, autonome systemen en edge AI-platforms.Naarmate AI-modellen groter en complexer worden, zullen toekomstige NPU’s blijven verbeteren door slimmere architecturen, computers met lage precisie, verwerking in het geheugen, lokale ondersteuning voor grote modellen, geavanceerd halfgeleiderontwerp en sterkere AI-beveiligingsfuncties.
Veelgestelde vragen [FAQ]
1. Waarom zijn NPU's efficiënter dan CPU's voor neurale netwerkworkloads?
NPU's zijn efficiënter omdat hun hardware specifiek is ontworpen voor AI-berekeningen in plaats van voor algemene verwerking.Een CPU voert veel verschillende systeemtaken opeenvolgend uit, terwijl een NPU zich voornamelijk richt op tensorbewerkingen, matrixvermenigvuldiging, convolutie en parallelle neurale netwerkverwerking.Hierdoor kunnen NPU's de AI-inferentie sneller voltooien, terwijl ze minder stroom verbruiken en minder warmte genereren.
2. Hoe verbetert parallelle verwerking de NPU-prestaties tijdens AI-inferentie?
NPU's verdelen AI-workloads in veel kleinere bewerkingen die tegelijkertijd over meerdere rekeneenheden worden uitgevoerd.In plaats van te wachten tot de ene instructie is voltooid voordat een andere wordt gestart, gaan grote hoeveelheden neurale netwerkgegevens parallel door de processor.Dit verbetert de doorvoer aanzienlijk en vermindert de latentie tijdens werkbelastingen zoals beeldherkenning, spraakverwerking en realtime objectdetectie.
3. Waarom is computergebruik met lage precisie belangrijk in moderne NPU's?
Veel AI-modellen vereisen geen extreem hoge numerieke precisie om nauwkeurige resultaten te produceren.NPU's gebruiken formaten zoals INT8 en FP16 om het geheugengebruik en de rekenkundige overhead te verminderen.Door verwerking met een lagere precisie kunnen meer bewerkingen in minder tijd worden voltooid, terwijl de energie-efficiëntie wordt verbeterd en de sterke AI-inferentieprestaties behouden blijven.
4. Hoe verminderen NPU's de knelpunten bij geheugenoverdracht in vergelijking met GPU's?
NPU's plaatsen geheugen- en rekenhardware dichter bij elkaar binnen de processorarchitectuur.In plaats van herhaaldelijk grote hoeveelheden tensorgegevens over te dragen tussen het externe geheugen en de verwerkingskernen, blijven veel tussenliggende bewerkingen in de buurt van de uitvoeringseenheden.Dit verkort de datapaden, vermindert het bandbreedtegebruik, verlaagt de latentie en verbetert de algehele energie-efficiëntie.
5. Waarom worden NPU's nuttig in smartphones en edge AI-apparaten?
Moderne apparaten vereisen snelle lokale AI-verwerking met een laag stroomverbruik en minimale latentie.Met NPU's kunnen smartphones en edge-systemen AI-taken zoals gezichtsherkenning, AI-fotografie, steminteractie en objectdetectie rechtstreeks op het apparaat uitvoeren zonder sterk afhankelijk te zijn van cloudservers.Dit verbetert het reactievermogen, de privacy en de batterijefficiëntie.
6. Hoe dragen MAC-eenheden bij aan NPU-versnelling?
Multiply-Accumulate (MAC)-eenheden verzorgen de herhaalde vermenigvuldigings- en optelbewerkingen die in neurale netwerken worden gebruikt.Moderne NPU's bevatten honderden of duizenden MAC-eenheden die tegelijkertijd werken, waardoor grote AI-workloads veel sneller kunnen worden verwerkt dan op traditionele sequentiële processors.
7. Waarom gebruiken moderne AI-systemen zowel GPU’s als NPU’s in plaats van te vertrouwen op één processortype?
GPU's en NPU's zijn geoptimaliseerd voor verschillende workloads.GPU's blinken uit in grootschalige AI-training, grafische weergave en krachtige parallelle berekeningen, terwijl NPU's zijn geoptimaliseerd voor AI-inferentie met laag vermogen en realtime lokale verwerking.Door beide processors samen te gebruiken, kunnen systemen flexibiliteit, prestaties en energie-efficiëntie in evenwicht brengen.
8. Hoe verbeteren NPU’s de realtime AI-verwerking in robotica en autonome systemen?
Robotica en autonome systemen verwerken voortdurend camera-invoer, omgevingskartering, sensorgegevens en bewegingsanalyse.NPU's versnellen deze werklasten lokaal met een lage latentie, waardoor systemen snel kunnen reageren tijdens navigatie, obstakeldetectie, voetgangersherkenning en realtime besluitvorming.
9. Waarom wordt AI op het apparaat belangrijker voor de toekomstige NPU-ontwikkeling?
AI op het apparaat vermindert de afhankelijkheid van cloud computing door AI-modellen rechtstreeks op lokale hardware te laten draaien.Dit verbetert de privacy, verlaagt het bandbreedtegebruik van het netwerk en maakt snellere realtime reacties mogelijk.Van toekomstige NPU's wordt verwacht dat ze grotere lokale AI-modellen, multimodale AI-verwerking en geavanceerde generatieve AI-workloads direct in consumenten- en industriële apparaten zullen ondersteunen.
10. Hoe kunnen toekomstige NPU-architecturen de efficiëntie van AI-hardware veranderen?
Toekomstige NPU's zullen waarschijnlijk slimmere toewijzing van werklasten, spaarzaam computergebruik, verwerking in het geheugen, chiplet-architecturen en adaptieve precisiecontrole gebruiken om de efficiëntie te verbeteren.Deze technologieën zijn bedoeld om onnodige berekeningen te verminderen, het energieverbruik te verlagen en de doorvoer te vergroten, terwijl ze grotere en geavanceerdere AI-modellen ondersteunen voor edge-apparaten, robotica, industriële systemen en intelligente consumentenelektronica.
Gerelateerde blog
-
Hoeveel nullen in een miljoen, miljard, triljoen?
![Hoeveel nullen in een miljoen, miljard, triljoen?]()
2024/07/29
Million vertegenwoordigt 106, een gemakkelijk te begrijpen figuur in vergelijking met alledaagse items of jaarsalarissen. Miljard, gelijk aan 109, beg... -
IRLZ44N MOSFET -datasheet, circuit, equivalent, pinout
![IRLZ44N MOSFET -datasheet, circuit, equivalent, pinout]()
2024/08/28
De IRLZ44N is een veelgebruikte N-kanaalmower MOSFET.Bekend om zijn uitstekende schakelmogelijkheden, is het zeer geschikt voor tal van toepassingen, ... -
Batterijtemperatuur te laag, opladen gestopt.Hoe het op te lossen?
![Batterijtemperatuur te laag, opladen gestopt.Hoe het op te lossen?]()
2024/10/6
Batterij oplaadproblemen voor mobiele telefoons komen vaak voor, maar kunnen effectief worden beheerd.Temperatuur speelt een grote rol bij de batterij... -
BC547 Transistor uitgebreide gids
![BC547 Transistor uitgebreide gids]()
2024/07/4
De BC547 -transistor wordt vaak gebruikt in verschillende elektronische toepassingen, variërend van basissignaalversterkers tot complexe oscillatorci... -
Uitgebreide gids voor SCR (siliciumgestuurde gelijkrichter)
![Uitgebreide gids voor SCR (siliciumgestuurde gelijkrichter)]()
2024/04/22
Siliciumgestuurde gelijkrichters (SCR), of thyristors, spelen een cruciale rol in de elektronische technologie van de kracht vanwege hun prestaties en... -
LR621, SR621SW, 364, AG1 -batterij -equivalenten en vervangingen
![LR621, SR621SW, 364, AG1 -batterij -equivalenten en vervangingen]()
2024/07/15
LR621 en SR621SW -batterijen zijn gangbaar in compacte elektronische apparaten zoals horloges, klein speelgoed, rekenmachines en externe toetsen.Meerd... -
Fundamentals van op-amp circuits
![Fundamentals van op-amp circuits]()
2023/12/28
In de ingewikkelde wereld van elektronica leidt een reis naar zijn mysteries ons steevast naar een caleidoscoop van circuitcomponenten, zowel voortref... -
Vergelijking van NMOS- en PMOS -verschillen en toepassingen
![Vergelijking van NMOS- en PMOS -verschillen en toepassingen]()
2024/11/15
Inzicht in de verschillen tussen NMO's en PMOS -transistoren is belangrijk bij het ontwerpen van efficiënte circuits.NMOS (N-type metaal-oxide-halfge... -
Een complete gids voor multiplexers en hun rol in digitale systemen
![Een complete gids voor multiplexers en hun rol in digitale systemen]()
2025/09/20
Multiplexers zijn componenten in digitale systemen, ontworpen om meerdere ingangssignalen te kanaliseren in een enkele uitgangsregel met behulp van bi... -
Wat betekenen STD, AGM en gel op een batterijlader
![Wat betekenen STD, AGM en gel op een batterijlader]()
2024/07/10
Traditionele batterijladers voor loodzure batterij staan bekend om hun eenvoud en betrouwbaarheid.Ze dienen hun doel al jaren effectief, grotendee...










Hete delen
- 08052C471KAT9A
- IP4338CX24
- XC4VFX100-11FFG1517C
- HY29F400BT-70
- C3216C0G2J102K085AA
- 06031A2R2CAT4A
- TPS76333QDBVRQ1
- GQM2195C2A3R9BB01D
- AD9508BCPZ-REEL7
- AD8582AN
- PT7C4372ALEX
- LM385Z-1.2/NOPB
- BU2841AFS
- CD74HC93M96
- RT0805DRD0724RL
- C1005X8R1C473K050BB
- MAX15004AAUE/VCO
- GRM1885C2A8R2CA01D
- XR20M1172IG28
- S29AL032D90TAI030
- GRM1555C1E8R8CA01D
- D121N1200B
- XC5VLX50T-2FFG1136C
- EMIF6-100LFC-LF-T73C
- QMK325B7473KN-T
- AVF4900B
- ZL30105QDG1
- 1206CC562MAT1A
- PBM39702/1-E1
- 1812SC471MATME
- S29GL064N90BFI030
- BD9305FVM-TR
- MB90F463APMC-G-SNE1
- QM75CY-12H
- LPC2294JBD144
- TSA5521M/C5
- GRM0336S1E2R5CD01D
- MT46V32M16P-6TIT:F
- 08053A151JAT2A
- VI-224-IX
- VI-JNN-EZ
- T495D156M035ATE260
- T491B476K010ZT7005ZV18
- R5F100MJAFB#30
- LT1767EMS8-2.5
- C0603X5R0J474KBC
- ZPSD311VB-20J
- STLC7545TQFP4Y
- BCM56850A2KFSBLG
- DS2460S-450-00+1T